Task: Put the M on Mona Lisa; Put the E on Einstein
Summary
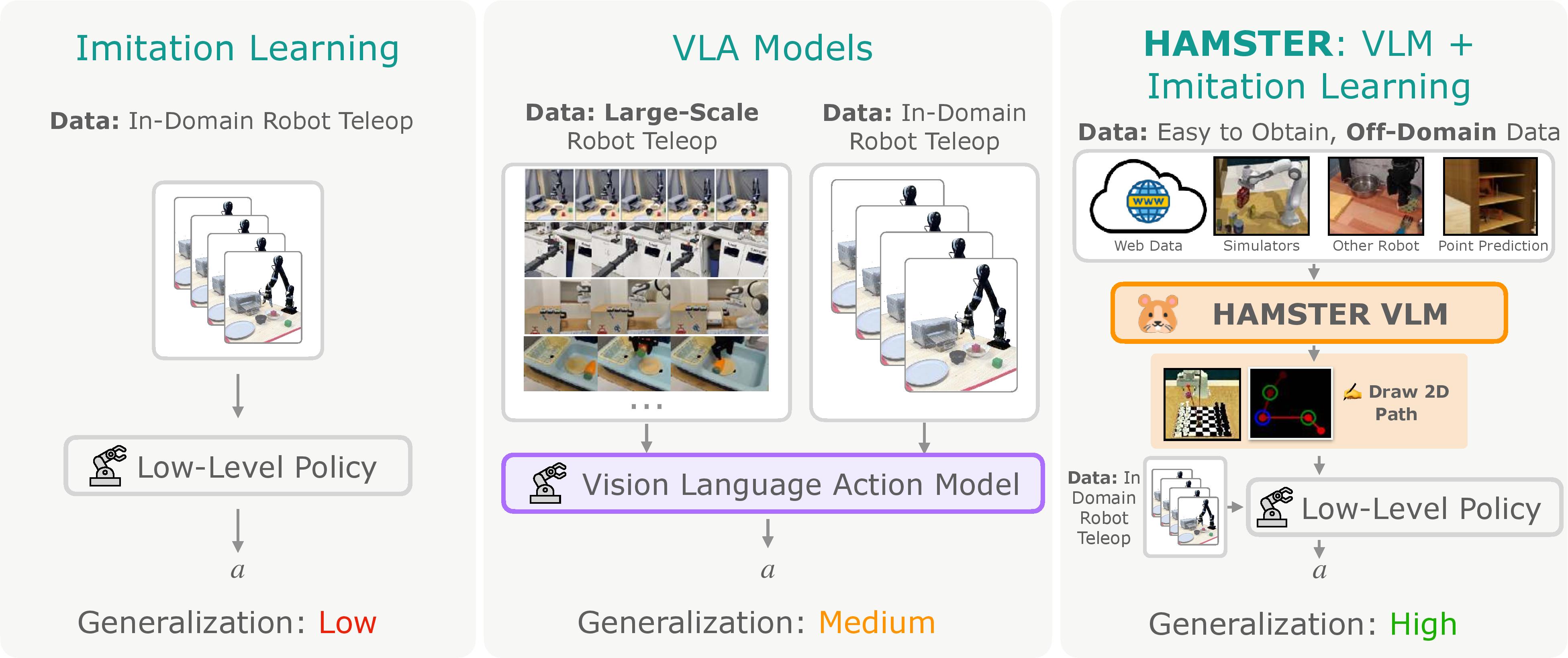
We propose a Hierarchical VLA architecture, HAMSTER, which can enable robotic manipulation with semantic, visual, and geometric generalization after being trained on easy to collect, off-domain data.
This allows us to combine the benefits of imitation learning models, which require little in-domain robot data, with those of large VLA models that can generalize well.
1. VLM and Policy Training
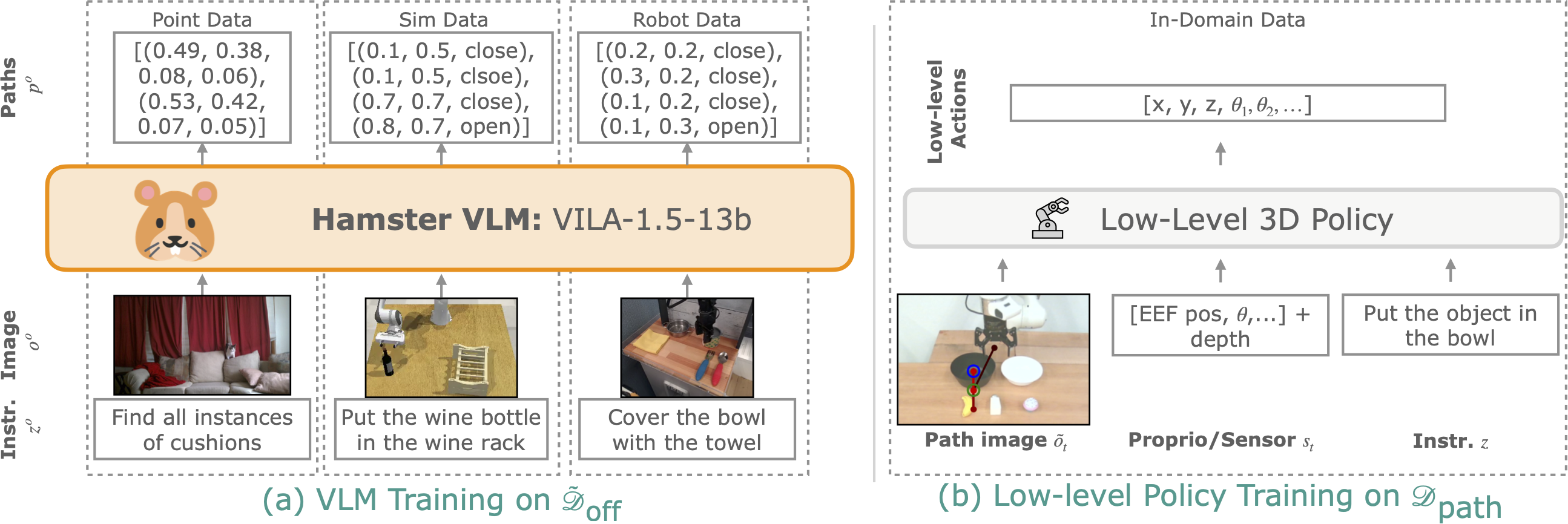
(a): First, we fine-tune a pre-trained VLM on a large, general, off-domain dataset $ \tilde{\mathcal{D}}_\text{off} $ to produce paths and points.
This includes robot simulation data and robot teleoperation data from environments different from the target environment.
(b): Then, we train a data-efficient, 3D-input policy on a small, in-domain dataset $ \mathcal{D}_\text{path} $ to produce actions conditioned on path-drawn images.
These path-drawn images help the policy generalize to new semantic, visual, and geometric task variations!
2. Inference
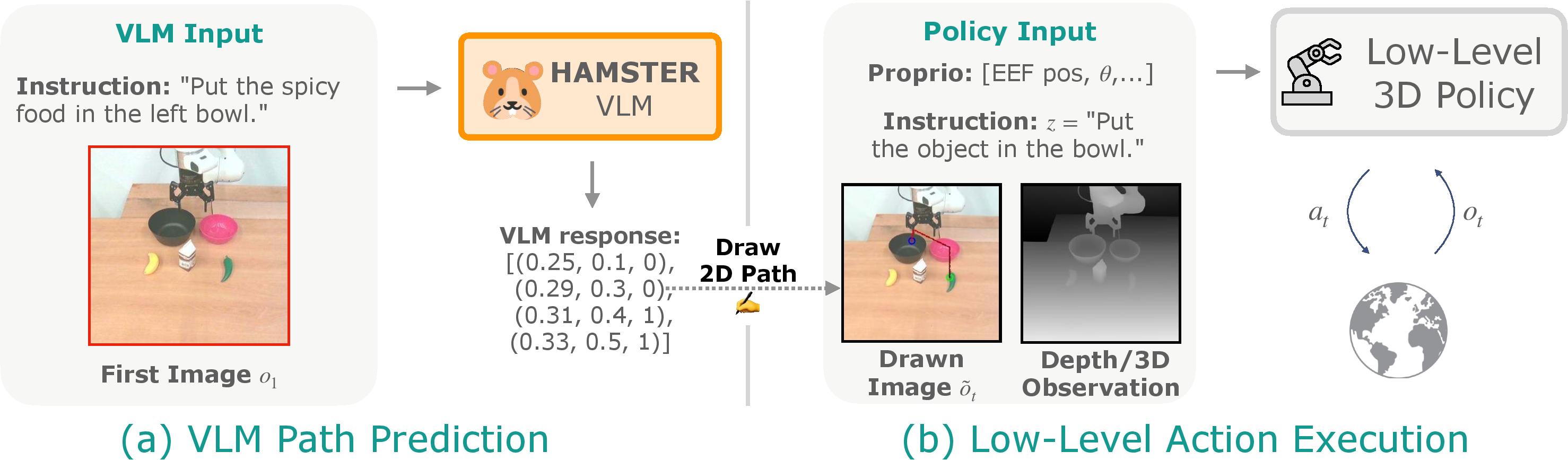
At inference time, we use the VLM to predict paths for the first observation $o_1$ conditioned on the text instruction.
These paths are drawn onto all images that the policy sees, $\tilde{o}_t$, where it then executes low-level environment actions.
Visual generalization comes from the fine-tuned VLM; expert low-level control comes from the separate low-level 3D policy.
Experiments and Results
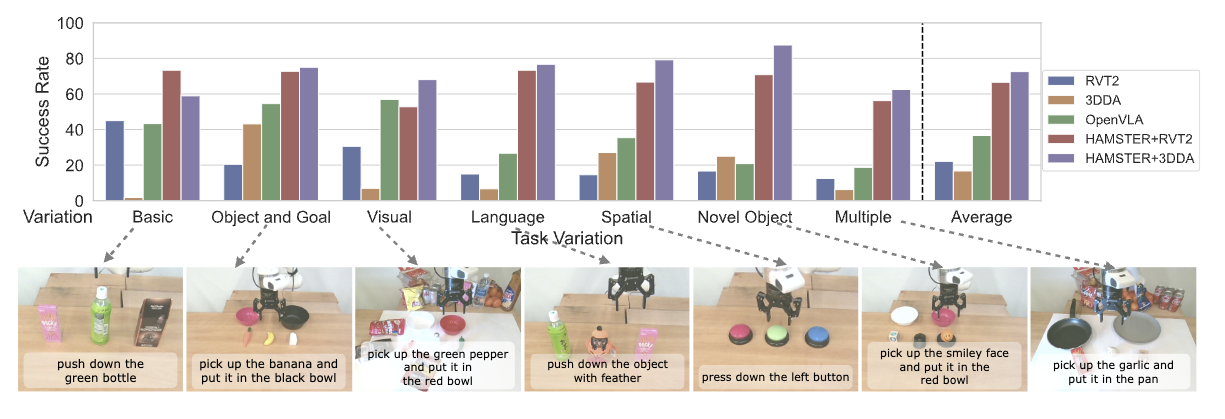
Overall results: HAMSTER outperforms OpenVLA and 3D imitation learning (RVT2, 3DDA) policies in generalization to new task variations. We separate results into a variety of sections demonstrating various capabilities of HAMSTER below:
Semantic Generalization
Task: Put the coke can on Jensen Huang
Task: Put the S block on the plate pointed to by the arrow
Long Horizon, Uninterrupted Task Execution
Off Domain Data VLM Fine-tuning helps with Path Generation
RLBench Simulation Data helps with path generation of real-world tasks similar to those in the off-domain dataset.

Comparison to RT-Trajectory which uses a pre-trained VLM to generate paths w/o fine-tuning. Fine-tuning on off-domain data to generate paths performs better!
| Method | VLM | Finetuning Data | Average Human Rank (lower is better) |
|---|---|---|---|
| RT-Traj. (Gu et al. 2023) | 0-shot GPT-4o | - | 3.47 |
| RT-Traj. (Gu et al. 2023) | Code as Policies GPT-4o (Liang et al. 2022) | - | 3.41 |
| HAMSTER (ours) | VILA (Lin et al. 2023) | Our off-domain data $ \tilde{\mathcal{D}}_\text{off} $ without simulated RLBench | 2.13 |
| HAMSTER (ours) | VILA (Lin et al. 2023) | Our off-domain data $ \tilde{\mathcal{D}}_\text{off} $ | 1.40 |
Human evaluation shows HAMSTER, with simulation data, excels in capturing spatial and semantic info across tasks, outperforming zero-shot VLM-based trajectory generation (Gu et al., 2023).
3D Aware Tasks
The 3D low-level policy can reason about various heights depending on the objects, despite being conditioned on identical paths! All 3 videos below are conditioned on the same path despite the objects being different
The low-level policy successfully puts the grapes into the white bowl.
The low-level 3D policy reasons about the different height of the milk carton to put it into the white bowl.
The 3D policy reasons about the different height of the red mug to successfully put the grapes into it.
Dexterous and Non-Prehensile
HAMSTER can perform dexterous and non-prehensile tasks.
Retaining Base VLM Capabilities
Despite fine-tuning HAMSTER still retains base VLM capabilities. For example, HAMSTER's VLM can generalize to new views:
Comparison against OpenVLA Pre-Trained with Our Sim Data
Unlike HAMSTER, OpenVLA does not improve when pre-trained with RLBench simulation data. Hierarchy helps enable cross-domain learning in VLAs!
HAMSTER
OpenVLA w/ RLBench Pre-Training
HAMSTER is Robust to Different Prompts
Below we demonstrate the HAMSTER's VLM path generation is robust to various input prompts. The first row contains the original prompt HAMSTER was trained with, and second row contains new prompts with changes bolded.
| Prompt | Drawn Path |
|---|---|
| Original Prompt: In the image, please execute the command described in <quest>move the coke to Taylor Swift</quest>. Provide a sequence of points denoting the trajectory of a robot gripper to achieve the goal. Format your answer as a list of tuples enclosed by <ans> and </ans> tags. For example: <ans>[(0.25, 0.32), (0.32, 0.17), (0.13, 0.24), <action>Open Gripper</action>, (0.74, 0.21), <action>Close Gripper</action>, ...]</ans> The tuple denotes point x and y location of the end effector of the gripper in the image. The action tags indicate the gripper action. The coordinates should be floats ranging between 0 and 1, indicating the relative locations of the points in the image. |

|
| In the provided image, perform the task described in <quest>have the coke on the lady</quest>. Generate a sequence of points representing the trajectory of a robot gripper to accomplish the objective. Present the output as a list of tuples encapsulated within <ans> and </ans> tags. For instance: <ans>[(0.74, 0.21), <action>Close Gripper</action>, (0.25, 0.32), (0.32, 0.17), (0.13, 0.24), <action>Open Gripper</action>, ...]</ans> |

|
HAMSTER Works with Different Low-Level Policies
| Policy | Averaged Success Rate (New Tasks) |
|---|---|
| RVT2 (Goyal et al. 2024) | 22.11 |
| HAMSTER + RVT2 | 66.56 |
| 3D-DA (Ke et al. 2024) | 16.70 |
| HAMSTER + 3D-DA | 72.55 |
HAMSTER performs well with different low-level policies (RVT2, 3D-DA), and demonstrates a significant performance improvement compared to the base policy with both.
BibTeX
@misc{li2025hamsterhierarchicalactionmodels,
title={HAMSTER: Hierarchical Action Models For Open-World Robot Manipulation},
author={Yi Li and Yuquan Deng and Jesse Zhang and Joel Jang and Marius Memmel and Raymond Yu and Caelan Reed Garrett and Fabio Ramos and Dieter Fox and Anqi Li and Abhishek Gupta and Ankit Goyal},
year={2025},
eprint={2502.05485},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2502.05485},
}